Cómo hice el deploy seguro de theos48.lat
La historia real de un deploy en VPS: orden correcto para TLS, build reproducible, script con lock y rollback sin pánico.
Cómo hice el deploy seguro de theos48.lat (sin drama de viernes)
Introducción: el deploy no falla por maldad, falla por optimismo
Este post continúa lo que conté en cómo construí este blog y por qué debí elegir Nuxt desde el día 1. Allá hablé de arquitectura de contenido; aquí toca la parte menos romántica y más útil: poner eso en producción sin romper nada.
Yo también tuve esa etapa de:
- “Es un portafolio, en una hora queda.”
- “Nginx es copiar-pegar.”
- “TLS lo veo al final.”
- “¿Por qué tengo logs gritándome?”
El stack era claro: VPS Ubuntu + Nginx + Let’s Encrypt + Node 24 + pnpm + Vite SSG. La complejidad no estaba en la tecnología. Estaba en el orden de ejecución.
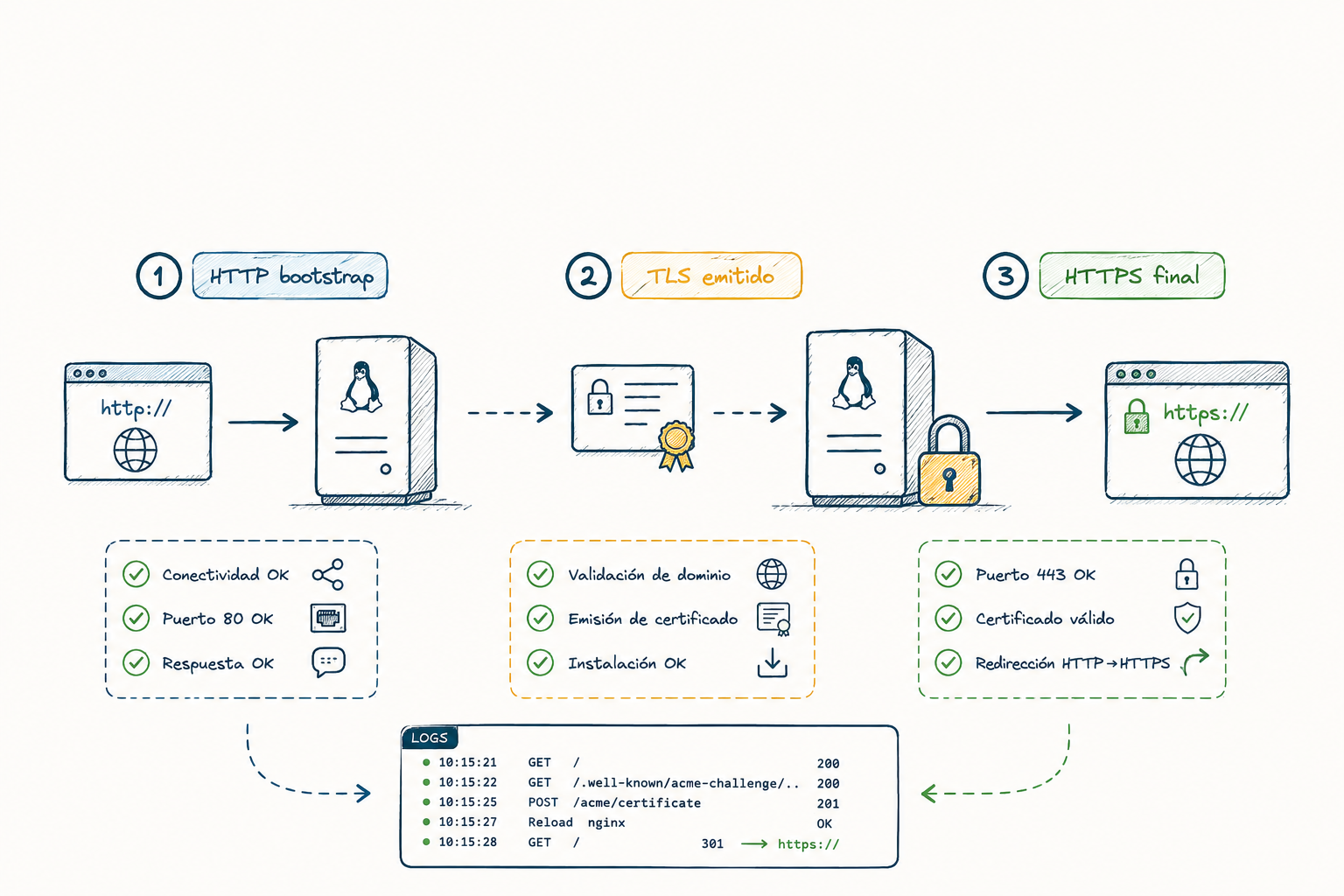
Error elegante #1: activar HTTPS antes de tener certificado
Sí, técnicamente puedes escribir primero el bloque 443.
También técnicamente puedes abrir un paraguas dentro de casa y decir que “estás listo para la lluvia”.
Lo que no conviene hacer
# Carga HTTPS final sin certificado emitido
server {
listen 443 ssl http2;
server_name theos48.lat;
ssl_certificate /etc/letsencrypt/live/theos48.lat/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/theos48.lat/privkey.pem;
}Radio de daño
nginx -trevienta.- No hay reload limpio.
- Frenas tu propio flujo de bootstrap.
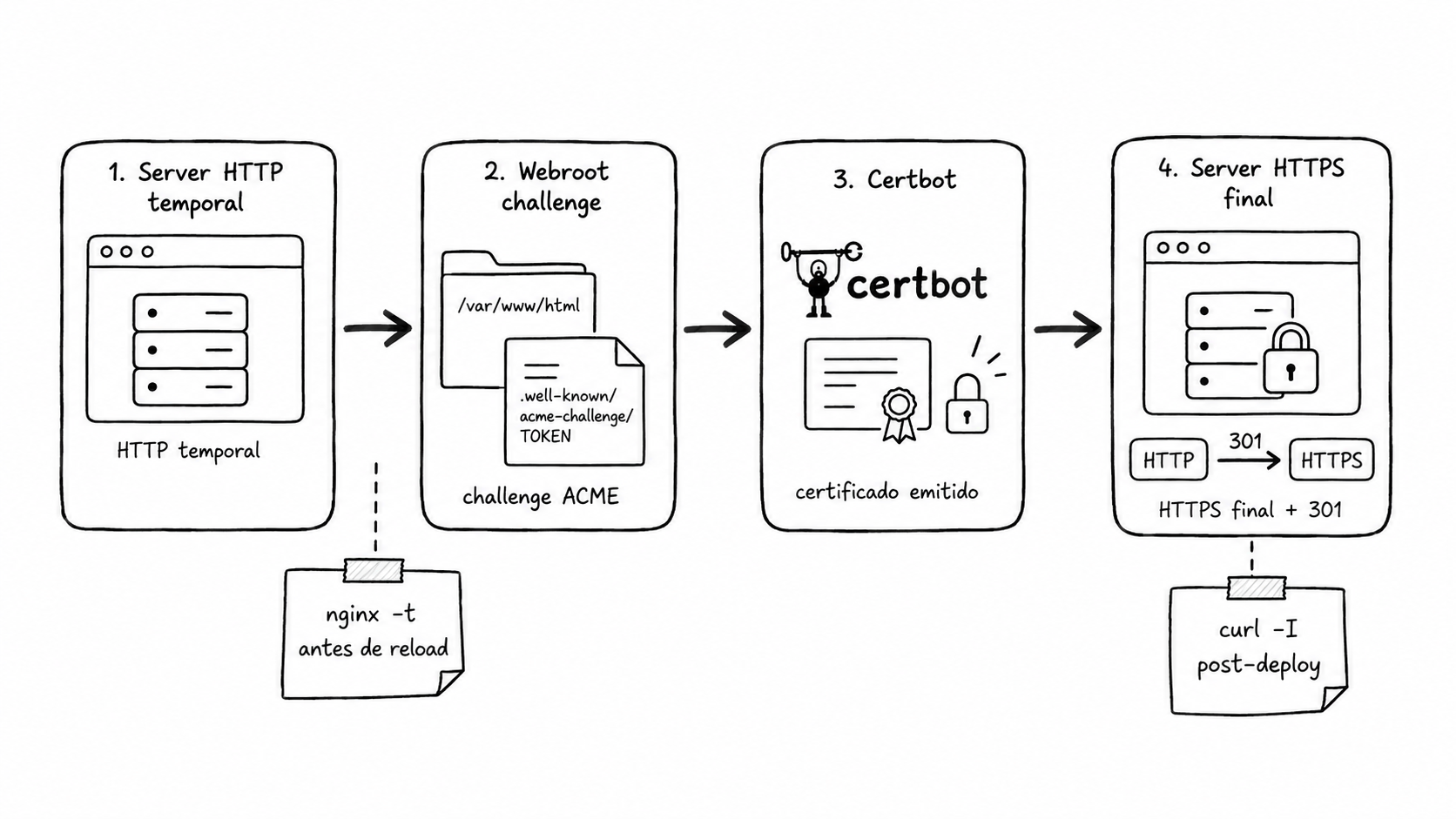
Reality check
Primero HTTP-only para challenge ACME, luego emites cert con Certbot en modo webroot, y después pasas a HTTPS final con redirección.
Error elegante #2: deploy sin lock “porque nadie más lo va a correr”
Una de las frases más caras de ingeniería: “tranqui, soy el único tocando esto”.
Anti-patrón
# Deploy manual sin candado ni trazabilidad
git pull
pnpm install
pnpm run build
sudo systemctl reload nginxRadio de daño
- Dos procesos de deploy pueden pisarse.
- Si algo falla, no sabes cuándo ni en qué paso.
- Rollback con memoria selectiva (“creo que sí corrí ese comando”).
Reality check
Script operativo con lock file, logs por timestamp y validaciones antes y después:
# Flujo oficial
deploy-portafolio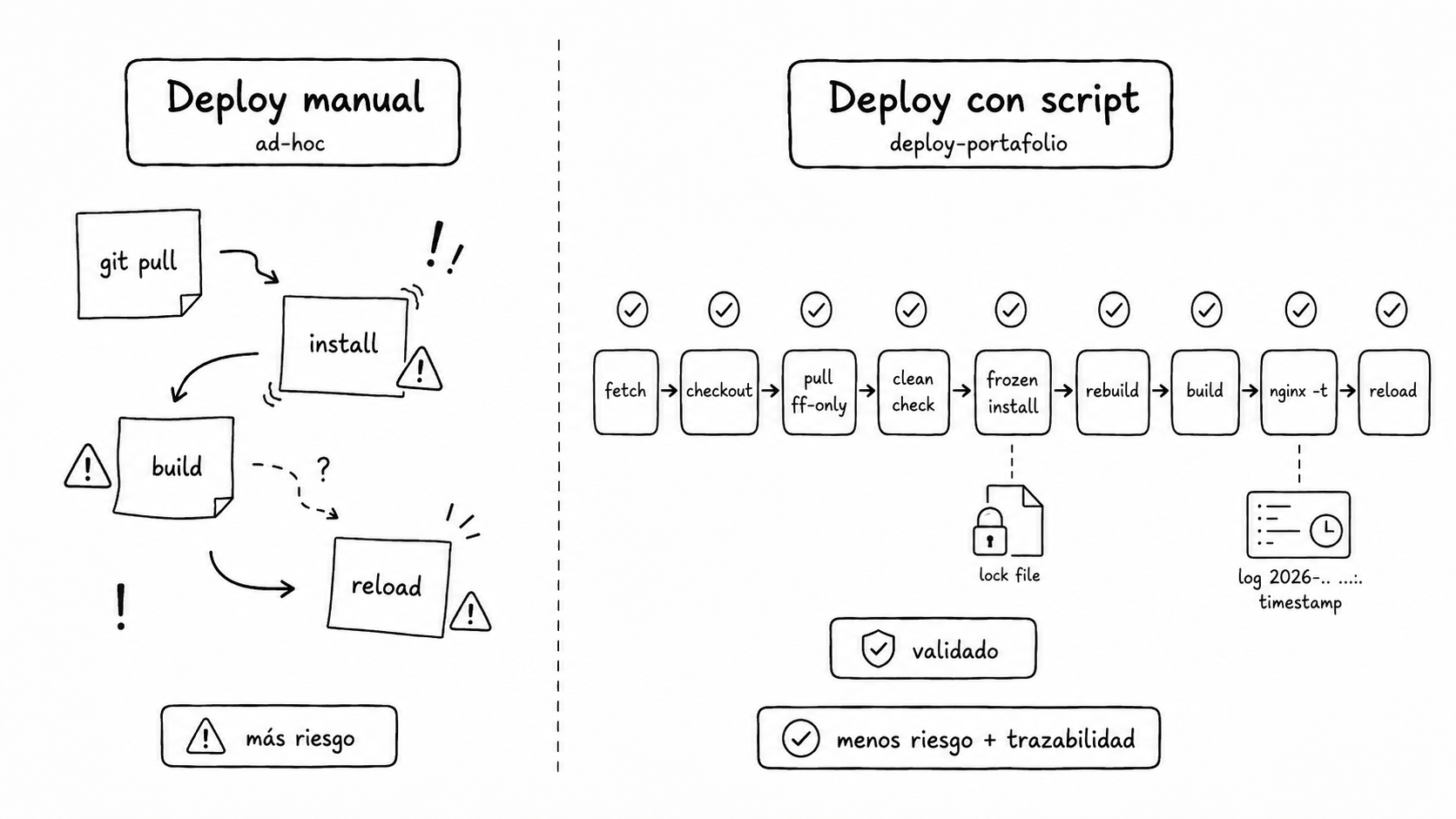
Error elegante #3: build “normalito” en producción
Hay una diferencia sutil entre “instaló” y “es reproducible”. La primera te da esperanza. La segunda te da sueño tranquilo.
Anti-patrón
# Ejecuta de todo, confía en todo
pnpm install
pnpm run buildRadio de daño
- Dependencias resueltas de forma no determinista.
- Scripts de instalación fuera de control.
- Build distinto según contexto.
Reality check
Congelar lockfile, bloquear scripts por defecto y habilitar solo rebuild explícito (documentación de pnpm install):
pnpm install --frozen-lockfile --ignore-scripts
pnpm rebuild sharp esbuild --config.ignore-scripts=false
pnpm run buildError elegante #4: recargar Nginx y asumir que “si no tronó, quedó”
Ese momento en que todo “parece bien” y te dan ganas de cerrar terminal rápido para no tentar la suerte.
Anti-patrón
# Sin verificación real
sudo systemctl reload nginxRadio de daño
- Problemas silenciosos en runtime.
- Deuda operacional disfrazada de éxito.
- Incidentes reportados por usuarios (la peor alerta posible).
Reality check
Checklist mínimo de cierre (incluyendo test de configuración nginx -t):
git -C /var/www/theos48.lat/portafolio status --short --branch
curl -I http://theos48.lat
curl -I https://theos48.lat
/usr/local/bin/check-theos48
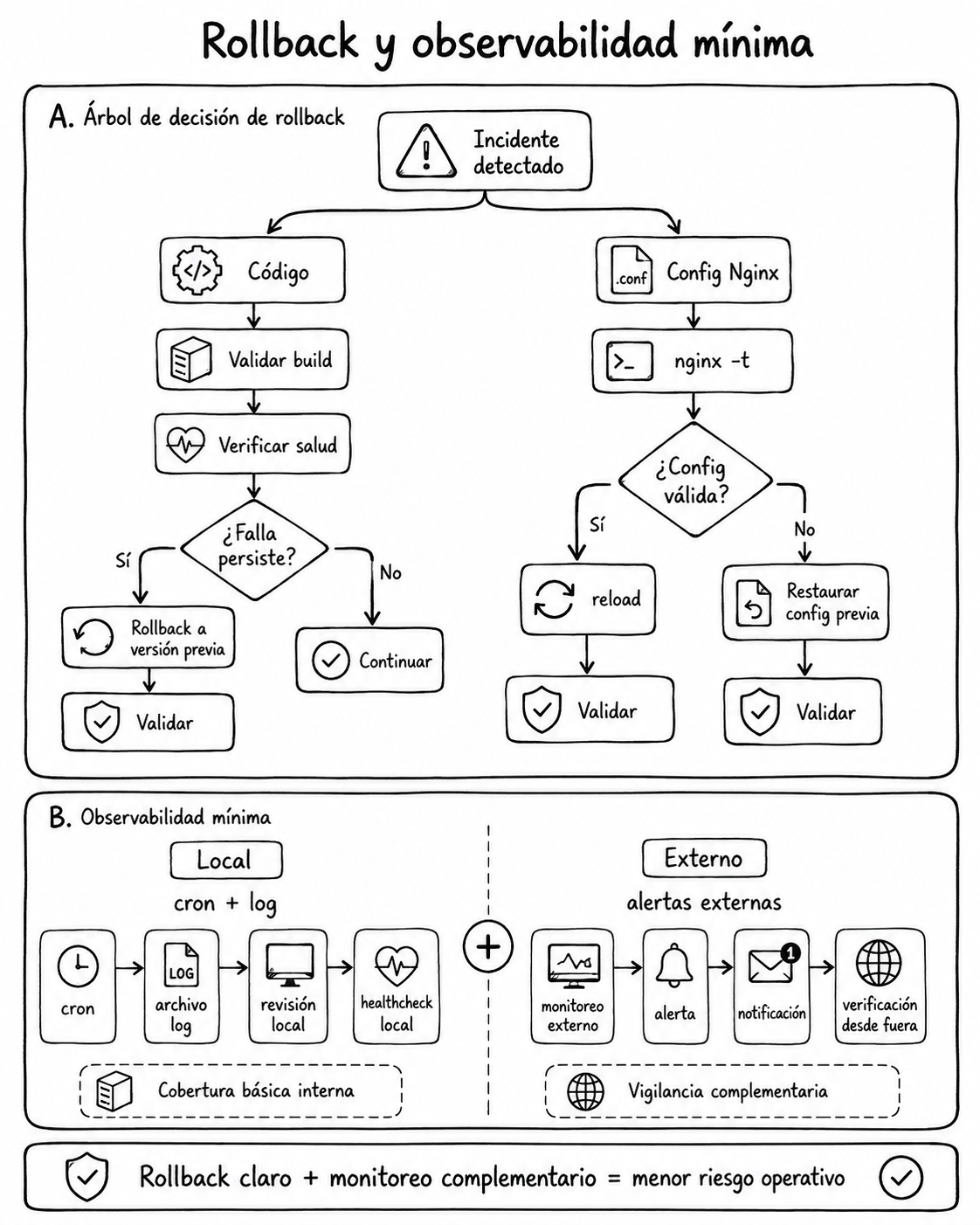
sudo nginx -tError elegante #5: creer que monitoreo local = observabilidad completa
El healthcheck local es útil. Pero si el VPS se cae completo, también se cae el que te avisaba que se cayó.
Anti-patrón
*/15 * * * * theos /usr/local/bin/check-theos48 >> /var/log/portafolio/healthcheck.log 2>&1Radio de daño
- Ceguera total ante caída de host.
- Detección tardía sin canal externo.
Reality check
Mantener healthcheck local para diagnóstico rápido y agregar monitoreo externo para alertas reales.
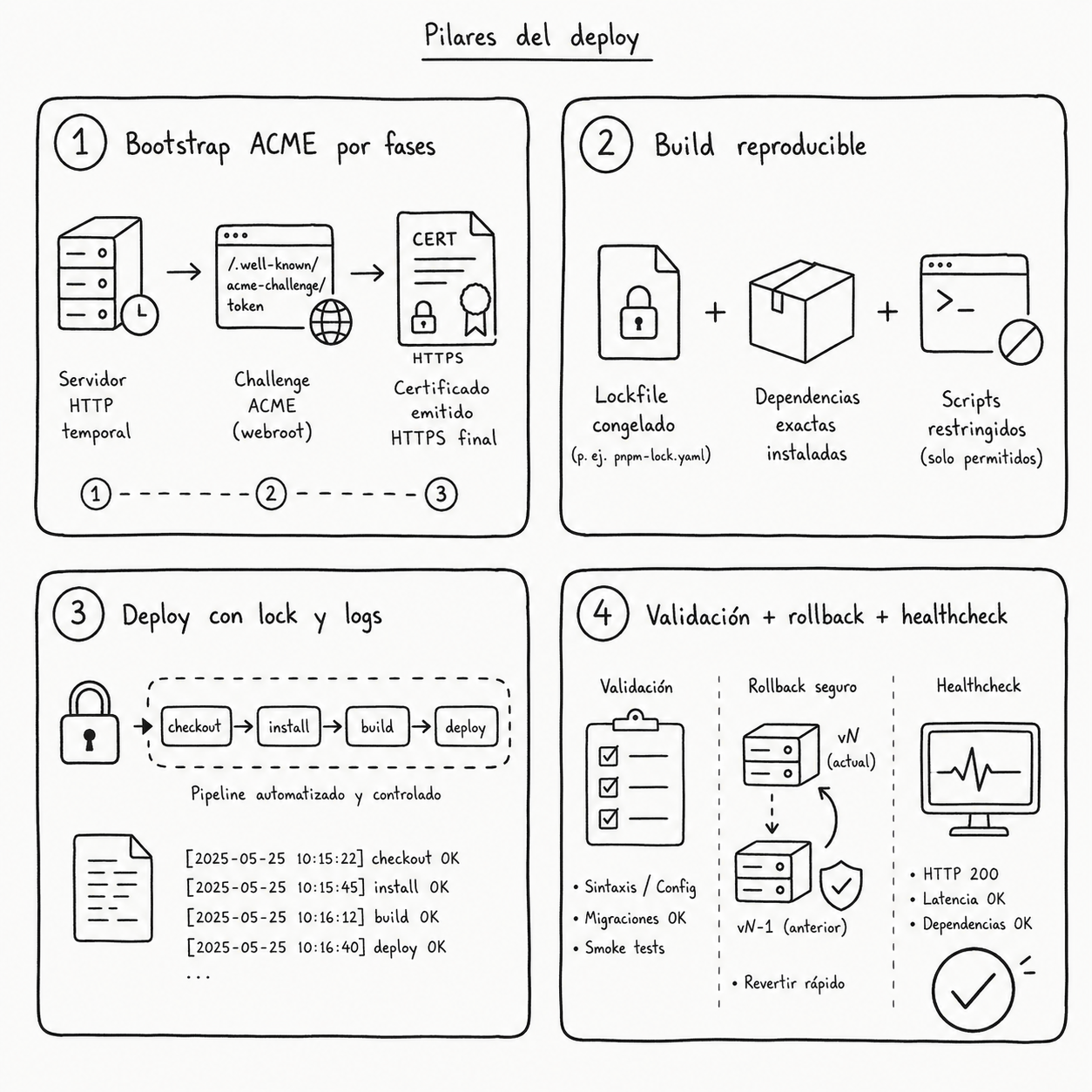
Mi flujo final (el que sí repetiría)
- Preflight: DNS, puertos, versiones, permisos.
- Build reproducible: lockfile congelado + scripts restringidos.
- Nginx por fases:
- HTTP-only para ACME.
- Emisión de certificado.
- HTTPS final + hardening.
- Deploy con script, lock y logs.
- Validaciones post-deploy.
- Rollback documentado (código + config).
Lo que mejoraría después de esto
- Pipeline de imágenes del cuerpo del blog con variantes modernas (
AVIF/WebP) y fallback limpio. - Monitoreo externo con alertas.
- Política de cache más explícita para assets estáticos.
Cierre
El deploy seguro no se siente épico. Se siente… aburridamente confiable. Y eso es exactamente lo que quieres en producción.
- Orden correcto evita fallos evitables.
- Reproducibilidad evita sorpresas.
- Validación + rollback evitan pánico.